
| Name: | Artem Sevastopolsky |
|---|---|
| Position: | Ph.D Candidate |
| E-Mail: | artem.sevastopolsky@gmail.com |
| Phone: | +49-89-289-19486 |
| Room No: | 02.07.035 |
Bio
I am a Ph.D. student at the Visual Computing & Artificial Intelligence lab. Previously, I worked as a researcher at the Vision, Learning and Telepresence lab at Samsung AI Center Moscow with the focus on 3D deep learning, differentiable rendering, point cloud processing and human telepresence. My previous degrees were obtained from Skolkovo University of Science and Technology (M.Sc.) and Lomonosov Moscow State University (B.Sc.), both in machine learning and computer science. I have also worked in medical imaging during the last years of my B.Sc. and in the industry. My current research is related to face recognition, active learning, and neural rendering. Homepage
Research Interest
neural rendering, 3D vision, face generation, novel view synthesisPublications
2025

| GaussianSpeech: Audio-Driven Gaussian Avatars |
|---|
| Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, Matthias Nießner |
| ICCV 2025 |
| GaussianSpeech synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. Our method can generate realistic and high-quality animations, including mouth interiors such as teeth, wrinkles, and specularities in the eyes. We handle diverse facial geometry, including hair buns and mustaches/beards, while effectively generalizing to in-the-wild audio clips. |
| [video][bibtex][project page] |

| Avat3r: Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars |
|---|
| Tobias Kirschstein, Javier Romero, Artem Sevastopolsky, Matthias Nießner, Shunsuke Saito |
| ICCV 2025 |
| Avat3r takes 4 input images of a person’s face and generates an animatable 3D head avatar in a single forward pass. The resulting 3D head representation can be animated at interactive rates. The entire creation process of the 3D avatar, from taking 4 smartphone pictures to the final result, can be executed within minutes. |
| [video][bibtex][project page] |

| HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs |
|---|
| Artem Sevastopolsky, Philip Grassal, Simon Giebenhain, ShahRukh Athar, Luisa Verdoliva, Matthias Nießner |
| 3DV 2025 |
| We learn to generate large displacements for parametric head models, such as long hair, with high level of detail. The displacements can be added to an arbitrary head for animation and semantic editing. |
| [code][bibtex][project page] |
2024

| TriPlaneNet: An Encoder for EG3D Inversion |
|---|
| Ananta Bhattarai, Matthias Nießner, Artem Sevastopolsky |
| WACV 2024 |
| EG3D is a powerful {z, camera}->image generative model, but inverting EG3D (finding a corresponding z for a given image) is not always trivial. We propose a fully-convolutional encoder for EG3D based on the observation that predicting both z code and tri-planes is beneficial. TriPlaneNet also works for videos and close to real time. |
| [video][code][bibtex][project page] |
2023
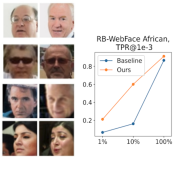
| How to Boost Face Recognition with StyleGAN? |
|---|
| Artem Sevastopolsky, Yury Malkov, Nikita Durasov, Luisa Verdoliva, Matthias Nießner |
| ICCV 2023 |
| State-of-the-art face recognition systems require huge amounts of labeled training data which is often compiled as a limited collection of celebrities images. We learn how to leverage pretraining of StyleGAN and an encoder for it on large-scale collections of random face images. The procedure can be applied to various backbones and is the most helpful on limited data. We release the collected datasets AfricanFaceSet-5M and AsianFaceSet-3M and a new fairness-concerned testing benchmark RB-WebFace. |
| [video][code][bibtex][project page] |
2020

| TRANSPR: Transparency Ray-Accumulating Neural 3D Scene Point Renderer |
|---|
| Maria Kolos, Artem Sevastopolsky, Victor Lempitsky |
| 3DV 2020 |
| An extension of Neural Point-Based Graphics that can render transparent objects, both synthetic and captured in-the-wild. |
| [video][bibtex][project page] |

| Neural point-based graphics |
|---|
| Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, Victor Lempitsky |
| ECCV 2020 |
| Given RGB(D) images and a point cloud reconstruction of a scene, our neural network generates extreme novel views of the scene which look highly photoreal. |
| [video][code][bibtex][project page] |
2019

| Coordinate-based Texture Inpainting for Pose-Guided Image Generation |
|---|
| Artur Grigorev, Artem Sevastopolsky, Alexander Vakhitov, Victor Lempitsky |
| CVPR 2019 |
| How would I look in a different pose? Or in different clothes? A ConvNet with coordinate-based texture inpainting to the rescue. |
| [code][bibtex][project page] |